

资源概况
购买将获得:完整论文报告+项目源码源文件+配置说明等
其他注意:一经购买,概不退款,不提供指导,每年数量有限,售完为止。
资源介绍(截取部分,完整请购买)


设计总说明
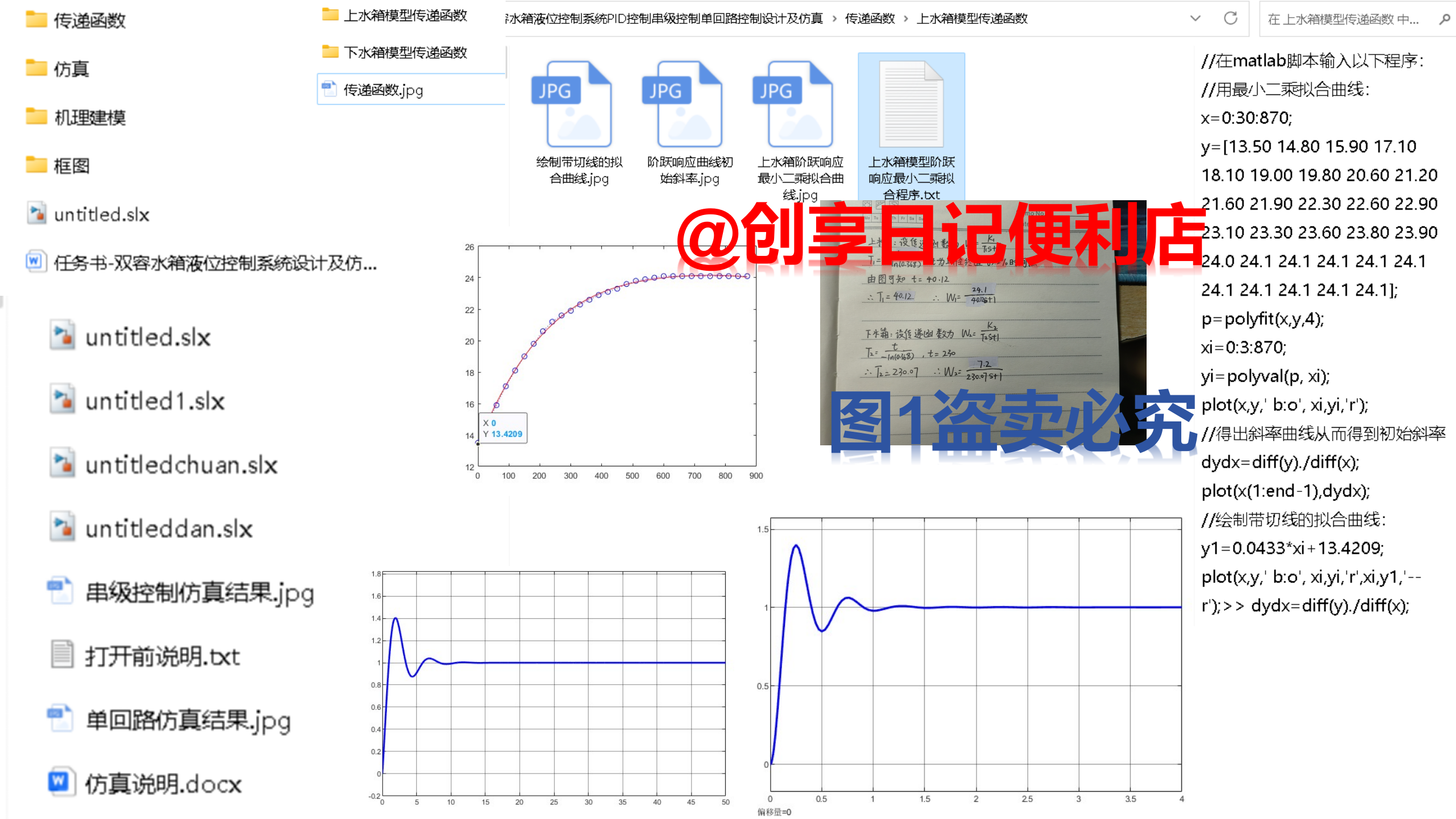
本文设计了一个个性化电影推荐系统,众所周知,现在电影资源是网络资源的重要组成部分,随着网络上电影资源的数量越来越庞大,设计电影个性化推荐系统迫在眉睫。所以本文旨在为每一个用户推荐与其兴趣爱好契合度较高的电影。
论文首先阐述推荐系统的研究现状以及意义,随后介绍了相关的推荐算法,重点介绍 协同过滤算法,并对系统实现所需技术进行了研究,接着介绍了整个推荐系统的实现,最后对整个项目进行了回顾与总结。本系统包含电影前端展示界面、电影评分板块、推荐算法的实现以及后端数据库的设 计.其中实现推荐算法是整个电影推荐系统的核心.系统采用由grouplens项目组从美国著名 电影网站movielens整理的ml-latest-small数据集,该数据集包含了671个用户对9000多部电 影的10万条评分数据.首先将该数据集包含的全部文件经过筛选重组之后存储到建好的数 据库中,并将数据集按一定比例划分为训练集和测试集,对训练集进行算法分析生成Top-N 个性化电影推荐列表,然后在测试集上对算法进行评测,至少包括准确率和召回率两种评测指标。协同过滤算法是推荐领域最出名也是应用最广泛的推荐算法.所以系统拟采用两种协 同过滤算法给出两种不同的推荐结果,一种是基于用户的协同过滤算法,另一种是基于物 品的协同过滤算法,用户可以根据两种推荐结果更加合理的选择合适的电影.系统采用了 改进之后的ItemCF-IUF和UserCF-IIF算法,对计算用户相似度和物品相似度的计算都做出 了改进.最后通过计算两种算法的准确率(Precision)、召回率(Recall)和流行度从而对系 统进行评测、并比较了两种算法各自的优势和劣势.实验证明,改进后的算法比原始的协 同过滤算法推荐效果要好,准确率更高。
整个系统涉及到的编程语言包含Python 、Html5、JQuery 、CSS3以及MySQL数据库编程,用到的框架是Django重量级web框架,通过该框架连接系统的前、后端.用户首先需要 填写用户名、密码以及邮箱注册系统,然后才能登陆推荐系统.进入首页后会看到8个电影 分类,包括恐怖片、动作片、剧情片等.用户需要给自己看过的电影进行评分,评分起止 为0.5-5.0分,共10个分段.每评价一部电影就要点击一下提交按钮,将所评分的电影的imdbId号以及对应的评分存入数据库中,用户点击“推荐结果 ”按钮,系统就调用推荐算法 遍历数据库所存数据,得出推荐列表之后将结果反馈给浏览器,同时调取数据库所存电影 海报图片进行展示.用户点击自己登陆的昵称,会跳转页面显示自己已经评价过的电影。
本文还分析了系统的需求,并对需求进行相关设计,最后用Django框架实现了该系统, 并给出了系统所用的主要数据表展示以及各个功能界面的展示。
1.1 研究背景及意义
1.2 国内外研究现状
1.3 本文研究目标和研究内容
本论文的研究目标是通过协同过滤算法实现一个个性化电影推荐系统:用户首先通过 填写用户名、密码、邮箱地址注册后进入系统,然后对系统主页所展示的8个类别的电影 中看过的电影进行评分,0.5分为最低分,满分为5分,所对应的评价分别是:不喜欢、一 般、喜欢、推荐.提交评分后浏览器将评分数据通过表单提交到数据库,推荐系统后台的 分析算法通过UserCF(基于用户的协同过滤算法)和ItemCF(基于物品的协同过滤算法)
给出两种推荐,即一个是基于用户之间的相似度,一个是基于电影之间的相似度。本文主要研究内容包括:
(1)研究原始的协同过滤算法,并调研应用该算法的视频网站.
(2)对原始的协同过滤算法做出改进,使推荐结果更加切符合用户兴趣.
(3)选定Top-N推荐的常用评价标准召回率和准确率与原始的协同过滤算法进行比较.
(4)以传统的协同过滤算法为基础,设计和实现一个个性化电影推荐系统,并从需求分析、系统设计、系统实现三个方面对该系统进行阐述.
1.4 论文结构安排
2.1 推荐算法简介
2.1.1 协同过滤算法
协同过滤算法[12]主要包括基于用户的协同过滤算法(UserCF)和基于物品的协同过滤
算法(ItemCF)两种推荐算法.
基于用户的协同过滤算法是推荐系统中最古老的算法,它是推荐系统诞生的标志[17] .
其主要包括两个步骤:
(1)找到和目标用户兴趣相似的用户集合
(2)找到这个集合中大多数用户都喜欢的,且目标用户没有买过或者看过的物品进 行推荐[18]
基于物品的协同过滤算法目前使用也很普遍.很多著名的视频网站如:Hulu、YouTube 推荐算法的基础都是该算法.该推荐算法的原理是向用户推荐和他们之前购买过的物品相 似度很高的物品.比如,该算法会因为你购买过《python编程从入门到实践》而给你推荐《用 python写网络爬虫》.主要分为两个步骤:
(1)计算各个物品间的相似度
(2)对物品的相似度从高到低进行排序,然后挑选一定数量的相似度较高物品进行 推荐.或者根据用户曾经的历史记录进行推荐.
2.1.2 基于内容的推荐算法
从每个物品中抽取一些特征,然后利用一个用户过去喜欢和不喜欢的物品的特征数据 来学习此用户的喜好特征.通过比较用户的特征和物品的特征,给用户推荐相似度较高的 物品.基于内容的推荐算法保护了用户之间的独立性,并且能很好的解决物品的冷启动问 题.
基于内容的推荐算法可以充分将项目内容和用户本身的诸多特征联系起来,比如一部 电影的演员、导演、类型,用户的性别、年龄、职业等.
其根据用户历史行为构造出用户偏好文档,计算所推荐的项目与用户偏好文档的相似 度,选择最相似的项目推荐给用户.首先为每个物品构建一个物品的属性资料,然后为每 个用户建立其一个喜欢的物品集,最后计算其和物品属性资料的相似度.相似度高意味着 用户可能喜欢这个物品,相似度很低则意味着用户会讨厌这个物品[13].
2.1.3 基于标签的推荐算法
标签是一种无层次化结构的、用来描述信息的关键词,可以描述物品的内涵特征.有 很多网站都利用了标签系统.比如:CiteULike论文书签网站,它允许科研人员收藏自己喜 欢的论文并给论文打上标签[21].还有国内的豆瓣网站,豆瓣网允许用户对电影以及图书等 打标签,系统利用打标签这个途径可以获悉图书和电影的内容以及所属类别.
2.2 系统实现算法介绍
2.2.1 基于用户的协同过滤算法

2.2.2 基于物品的协同过滤算法

2.3 相似度计算
2.4 推荐算法评测指标
其余完整内容详见下载
本章将改进后的基于用户的协同过滤算法和基于物品的协同过滤算法相结合应用到
实际中,做出了个性化的电影推荐系统.本章首先对国内外的主流视频网站进行了调研,然 后讲解系统的需求分析,介绍系统架构以及数据库,最后展示系统界面.
4.1 国内外主流视频网站推荐效果调研
4.2 需求分析
随着电影市场的迅速发展,每天都有大量电影上映.人们都希望可以高效的在海量电
影库中找到自己可能会喜欢的电影,以节省寻找电影的时间[22] . 电影推荐系统能给用户带来 便利.本文要实现的是一个面向用户的个性化电影推荐系统,根据movielens 数据集里面大 量用户对电影的评分数据,通过计算用户相似性、电影相似性,实现为用户推荐符合其兴 趣的电影.
本文实现的个性化电影推荐系统有以下几点基本需求:
(1)数据集:每个用户所评电影数量要多,尽量广泛涉及大量电影
(2)推荐算法:推荐效果要良好
(3)包括用户注册登录在内的整个web 系统
(4)系统要易于扩展和维护
4.3 用户功能需求
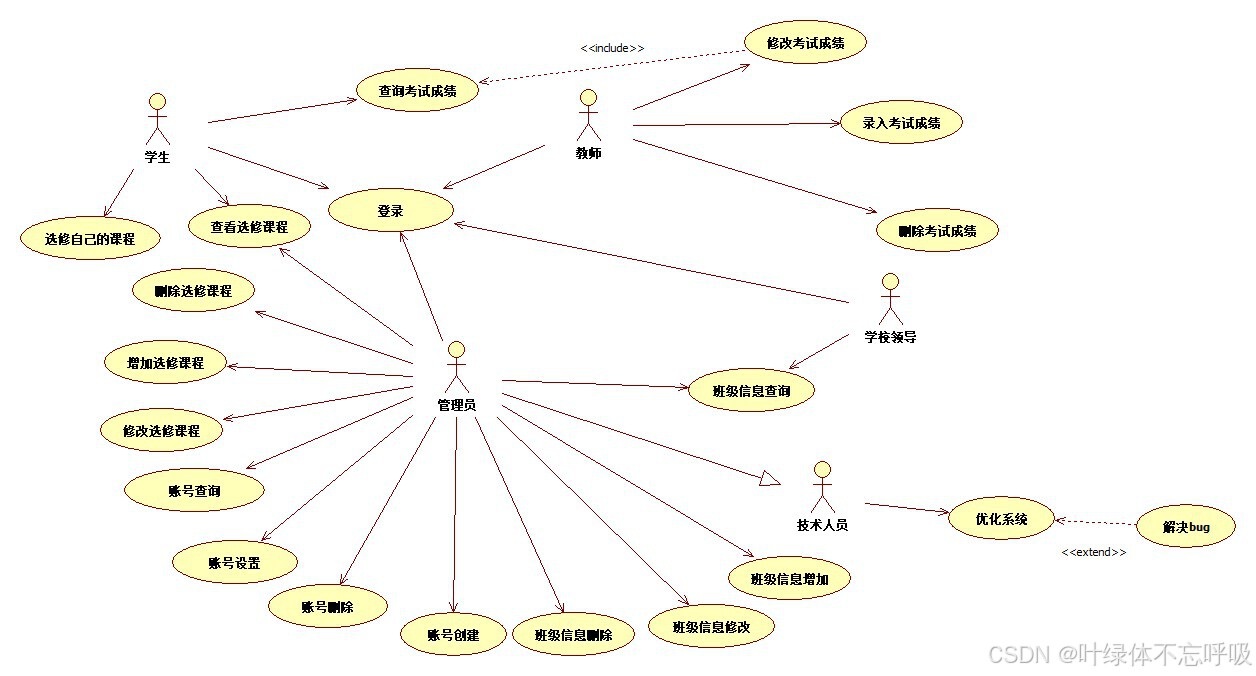
如图 4-6 是系统中用户的用例图,有 5 个用例,分别是注册、登录、注销、评分、查看推荐结果。

4.4 系统设计
4.4.1 系统总体架构
本文从互联网上下载movielens 数据集,经过数据重组和筛选,基于两种推荐算法得出推荐结果保存至 MySQL 数据库中,并通过 Django 框架进行前端展示.本系统采用 B/S(浏 览器/服务器)体系结构,用户通过浏览器就能和网站上的内容交互.
实现本系统主要需要以下几种编程语言:
(1)Python:进行后台开发,写推荐算法,和 MySQL 数据库交互,将用户的数据存储到数据库中,又将生成的推荐列表展示到前端页面
(2)Html5:进行前端页面的开发.
(3)Css3:美化前端页面,特别是对电影分类板块做处理.
(4)Jquery:实现提交表单和首页中的星星评分效果.
系统的总体架构设计图如图 4-7 所示.

一个良好的推荐系统,必须要有一个良好的用户交互界面和用户行为数据[16].其之间的 关系如图 4-8 所示.

4.4.2 系统功能模块简述
本系统以改进后的用户协同过滤和物品协同过滤算法为依据,采用 django 重量级 Web框架设计并实现.包括了数据集处理模块、注册登录模块、电影分类模块、用户评分反馈模 块、推荐算法模块和推荐电影展示模块.
① 数据集处理模块
本文设计的推荐系统的源数据集来源于 movielens 的 ml-latestl-small,其中包含671个用户的 10 万条评分数据.对数据集里面的 ratings.csv 和 links.csv 文件进行连接处理,只保 留 userId 、imdbId 、rating 三个字段存入数据库中新建好的数据表 users_resulttable 中.
② 注册登录模块
用户只有先注册并且登录系统之后才能提交对电影的评分.注册界面含用户名、电子 邮箱地址以及密码.注册和登录界面如图4-9 所示.

用户注册界面的核心代码如下:
@register.html
<div class="unit-1-2 unit-1-on-mobile">
<h3>注册</h3>
<form class="form" action="{% url 'users:register' %}" method="post">
{% csrf_token %}
{% for field in form %}
{{ field.label_tag }}
{{ field }}
{{ field.errors }}
{% if field.help_text %}
<p class="help text-small text-muted">{{ field.help_text|safe }}</p>
{% endif %}
{% endfor %}
<button type="submit" class="btn btn-primary btn-block">注册</button>
</form>
<div class="flex-center top-gap text-small">
<a href="login.html">已有账号登录</a>
</div>
</div>
其余完整内容详见下载
③ 电影分类模块
系统首页一共有 8 种类型的电影,如 4-10 所示. 从左到右依次是动作片、恐怖片、喜剧片、动画片、科幻片、犯罪片、爱情片以及剧情片

图 4-11 是爱情片的展示界面



④ 用户评分反馈模块
系统利用了 jquery-raty 评分插件,收集用户对每一部电影的评分.用户通过点击‘提交评分’按钮将评分数据提交到 MySQL 中的 users_resulttable 表中,插入到源数据集末尾.

⑤ 用户评分记录模块
用户登录系统后点击自己的昵称,将跳转页面显示自己曾经评价过的电影列表.如图4-15 所示
⑥ 推荐算法模块
本模块是整个系统的核心组成部分,当用户登录进入系统并对电影进行评分之后,系统就记录下了该用户的 id 号,当用户再次登入系统时,系统会将源数据集和该用户之前的评分数据整合成新的数据表作为推荐的依据. 整个推荐过程流程图如图 4-16 所示

算法生成推荐电影的 imdbId 号之后存入 matrix 全局变量列表中,并在 moviegenre 数据表中查询到相关的电影名称以及电影海报的链接,将 userId、title、poster 数据插入到users_insertposter 数据表中,此表即为所有登录用户的电影推荐列表集.得出用户的电影推荐结果并插入数据表中的核心代码如下:(篇幅有限,详见文末)
⑦ 显示推荐模块
根据登录用户对电影的评分反馈,通过基于用户的协同过滤和基于物品的协同过滤算法给出图 4-17 和图 4-18 两种推荐结果.

4.5 数据库介绍与设计
4.5.1 实验数据集介绍
本实验采用的数据集是由 GroupLens 科研小组从电影网站 MovieLens 上统计的ml-latest-small 数据集,该数据集包含了从 1995 年到 2016 年 10 月内 671 名用户对 9125 部电影的评分记录,一共 100004 条电影评分.里面的每一名用户评价的电影数量都不少于 20部.该 ml-latest-small 数据集由四个 csv 文件组成,分别是 ratings.csv、movies.csv、links.csv以及 tags.csv[25].下面将一一介绍. ratings.csv 是用户评分信息表,第一行是 4 个 title:userId(用户 id)、电影 id(movieId)、用户评分(rating)以及 timestamp(时间戳),其中用户评分区间为 0.5 分-5 分.表 4-1 即为ratings.csv 文件的节选.movies.csv 是电影属性表,包含三个字段,分别是 movieId(电影的 id号)、title(电影名称)、genre(电影的题材),表 4-2 即为 movies.csv 文件的节选。

其余完整内容详见下载
4.5.3 系统 E-R 图
数据库模型通常包括层次模型、网状模型、关系模型以及 ER 图(实体-联系图)系统的 E-R 图如图 4-23 所示

其余完整内容详见下载








暂无评论内容