资源概况
购买将获得以下全部内容:
- 数据集(已全部标注),可单独购买:https://www.csds.chat/2785.html
- 完整系统(数据集+训练好模型+UI界面+运行说明),可单独购买:https://www.csds.chat/2841.html
- 配套论文报告(查重30%以下),可单独购买:https://www.csds.chat/2827.html
其他注意:
- 一经购买,概不退款,不提供指导,每年数量有限,售完为止。
- 可额外付费50元,远程操作配置环境跑通程序,请加微信:P1313918
资源介绍(截取部分,完整请购买)




设计总说明
在许多非机动车交通事故中,未佩戴头盔是造成驾驶人受伤或死亡的主要原因,检测和惩处此类骑手对于降低道路交通事故严重性与保障人生命财产安全具有重要意义。针对该问题,目前交管部门主要采取交警现场执法这种监管方式,该方式需要投入巨大的人力物力,且效率低下。随着深度学习和目标检测技术的发展,越来越多的基于深度学习的智能系统应用于交通识别的场景中,因此,本文研究并设计了基于深度学习的电动车头盔佩戴检测系统,主要基于改进及训练后的YOLOv5模型对未佩戴头盔该违规行为进行识别,该系统可以辅助交管部门对非机动车进行监管,具有一定的现实意义与实用价值。
本设计的主要标准是算法准确性和实时性。算法准确性要求检测结果正确率高,误报率低;实时性则要求算法能够在短时间内完成检测并输出结果。本设计的设计原则是综合考虑算法的准确性和实时性,选用适合的深度学习模型进行训练,并结合数据集特点进行优化。同时,要充分考虑实际使用场景中可能出现的干扰及操作的便捷性,针对性地进行算法优化及可视化设计。综上所述,本设计选择Pytorch对YOLOv5模型进行训练,根据数据集和实际场景骑手头部目标较小的特点,使用Mosaic-9数据增强和添加CBAM注意力机制对原模型进行改进。
本设计的具体步骤如下:
(1)数据采集:本次电动车头盔佩戴检测数据集由MS COCO大型目标检测数据集和互联网中收集的非机动车道交通情况的数据集组合而成。
(2)数据标注:利用labelimg标注工具对数据集中的佩戴头盔、未佩戴头盔和非机动车三类进行标注,并进行格式转换和划分,得到训练数据集。
(3)模型训练:选用YOLOv5框架训练模型,并使用优化算法对模型进行调参和优化。
(4)分析改进:针对数据集特点和实际应用场景下的目标特点,提出并进行Mosaic-9数据增强和添加CBAM注意力机制优化。
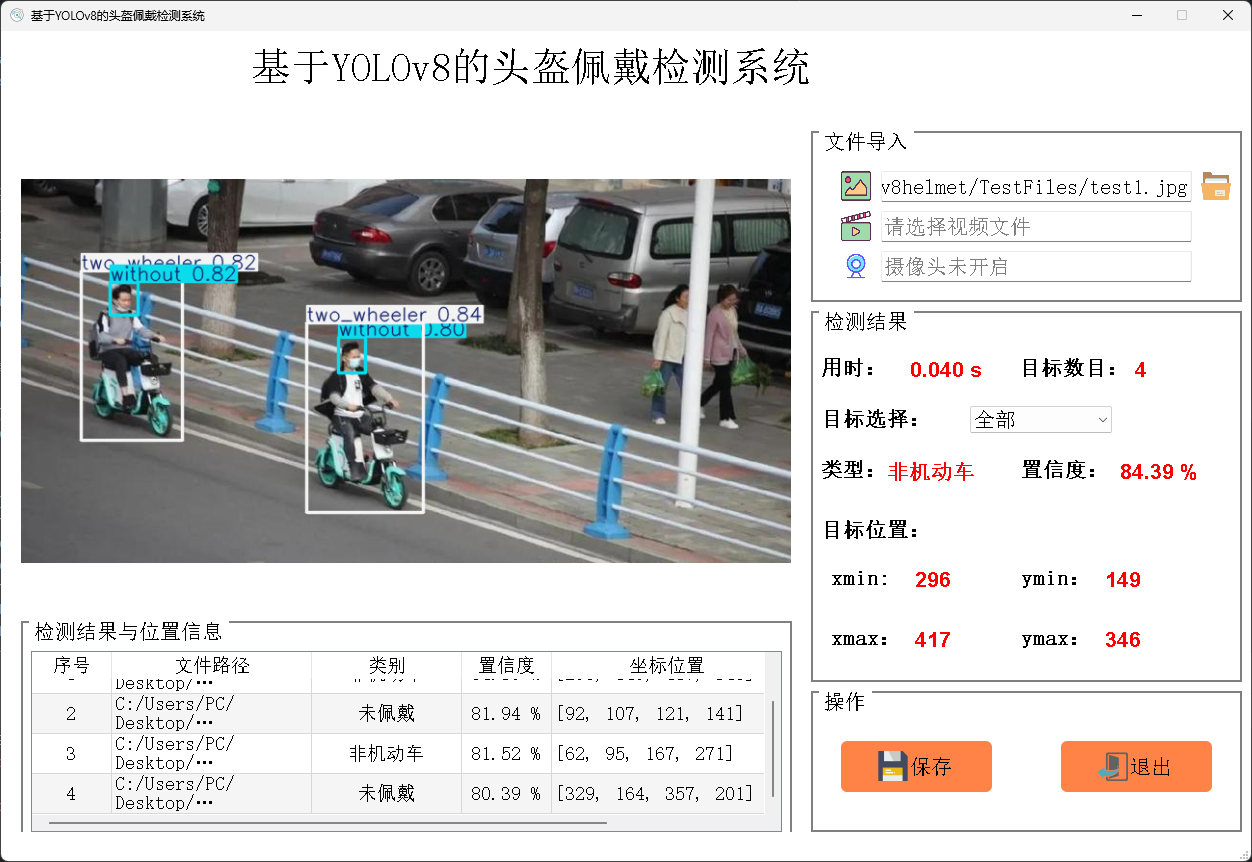
(5)实验验证:对不同场景下目标进行实验验证,评估算法的准确性和实时性。并且基于PySide6实现可视化操作界面。
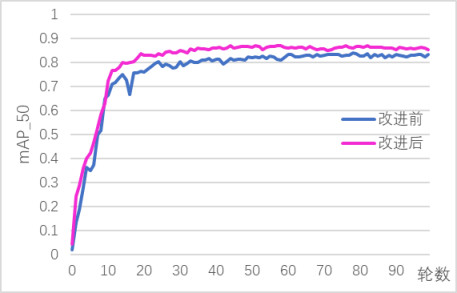
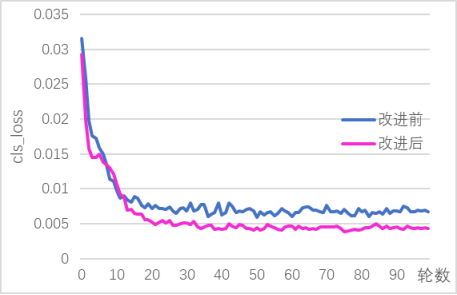
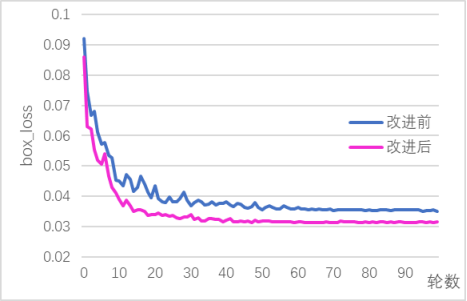
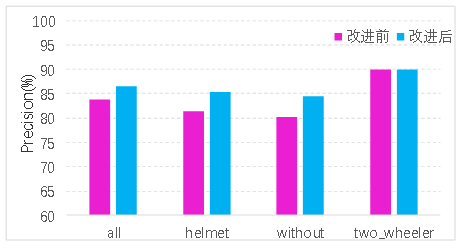
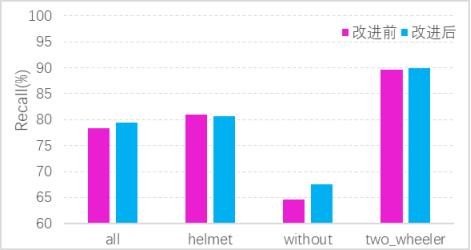
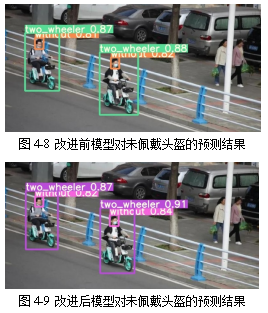
本设计最终实现了基于YOLOv5的电动车头盔佩戴检测算法,该算法能够在实时性和准确性方面达到较高的水平。实验结果表明,改进后的模型在保持实时性为49FPS的情况下,均值平均精确度相比原始的YOLOv5模型从原来的83.3%提升到了85.3%,精确率从 83.8%上升到了86.5%,召回率从78.4%上升到79.4%。相较于原先的模型,改进后的 YOLOv5模型在小目标检测上优势明显,能在保持YOLOv5检测实时性的同时,提高是否佩戴头盔和是否为非机动车的检测和分辨效果。同时,针对实际使用场景中可能的干扰因素,本设计还进行了一定的优化改进,提高了算法的鲁棒性和稳定性。
关键词:目标检测;深度学习;YOLOv5算法;头盔佩戴
第1章 绪论
在许多电动车交通事故中,未佩戴头盔是造成驾驶人受伤或死亡的主要原因,识别和惩处此类骑手对于降低道路交通事故严重性与保障人生命财产安全具有重要意义。本章将首先介绍电动车头盔佩戴检测的研究背景和意义,随后介绍目标检测的国内外发展现状,在最后部分将会概述全文结构。
其余完整详见下载
第2章 YOLO算法原理
本章主要介绍采用卷积神经网络的YOLO算法。首先,本章阐述卷积神经网络的原理及其组成。随后,对YOLOv5网络结构进行分析,并描述其检测流程。最后,本章介绍了一些常见的模型评价指标,以便更好地评估YOLO模型的性能。

第3章 数据集分析和算法改进
本章首先对数据集和YOLOv5模型进行了分析,虽然YOLOv5是一种性能优异的通用目标检测算法,但在特定数据集上,其可能存在着一些问题,例如目标数量不均衡、目标过小等。这些问题可能会影响模型在该数据集上的检测效果和性能表现。为了解决这些问题,本章基于分析,提出了相关的改进措施。
3.1 头盔佩戴数据集分析
本次电动车头盔佩戴检测数据集由MS COCO大型目标检测数据集和网络中收集的非机动车道交通情况的数据集组合而成。通过labelimg软件对所有收集的图片进行标注,先标注为XML格式,再通过Python脚本转换为YOLO格式,并将其进行划分,代码详解附录B。处理完成的数据集一共有1164张图片用于训练,299张图片用于验证。其中检测的类别包含电动车及摩托车(two_wheeler)、佩戴头盔(helmet)和未佩戴头盔(without)三类,每个类别的实例数量如图3-1所示。其中,电动车及摩托车(two_wheeler)类共有3604个,佩戴头盔(helmet)类共3087个,未佩戴头盔(without)类共1760个。具体而言,数据集中未佩戴头盔类的检测实例数量较少,导致类别不均衡问题,可以通过数据增强处理来改善此问题。另外,数据集中存在许多较小的目标,占比约为44.52%。在这种情况下,可以添加CBAM注意力机制以改进小目标检测效果。总之,在解决目标检测问题时,需要针对数据集中的具体情况进行相应的处理和优化,以提高模型的检测准确率和性能。

3.2 YOLOv5分析
YOLOv5通过使用路径聚合网络和改进的网络骨架,显著提高了小物体检测效果。同时,对于大目标检测,该模型采用了多尺度训练和PAN模块来提高检测精度。多尺度训练可以从不同的尺度下学习到更多特征信息,而PAN模块则将不同尺度的特征信息融合起来,有效提高了检测精度。
然而, 由于小目标的面积较小且分辨率低,YOLOv5模型容易忽略或误分类这些目标。此外,该模型采用的anchor-based方法限制了检测框的大小和形状,因此在小目标检测方面表现不如一些anchor-free方法。这些问题可能导致在检测密集小物体时存在定位失误的问题,并且还容易将背景错误判别为物体。针对这些问题,可以尝试使用其他更适合小目标检测的模型或方法,或者采用更加细致和精确的参数调整方式来改进模型性能。
3.3 YOLOv5改进
由上述对于数据集和YOLOv5模型的分析,得知检测类别数量不均衡且数据集中的小目标较多,因此,针对具体问题提出以下改进方法。
3.3.1 Mosaic-9数据增强
为了解决图3-1中的数据不均衡问题,本文选择采用数据增强方法以增加数据量。数据增强是一种预处理技术,可以通过微小的变换操作使神经网络将其视为全新的图片,从而减少过拟合并提高模型效果。本文采用了Mosaic-9数据增强方法,将9张图片随机缩放、翻转、调整色域等,然后拼接起来。在实际应用中,数据增强是一种简单有效的方法,可用于解决数据不足和数据不均衡等问题,提高模型的表现和泛化能力。图3-2展示了Mosaic-9数据增强在本次设计的数据集上的效果图。

3.3.2 添加CBAM注意力机制
通过对数据集的分析得知小目标对象占到了44.52%,并且道路交通背景较为复杂,作为检测对象的骑手头部被遮挡情况较多,在此问题下,若要提高目标检测和定位的精度,可以将CBAM注意力机制引入YOLOv5网络主干。CBAM模块可以增强网络在关键区域的响应,更好地捕捉目标物体的细节和特征,并引入上下文信息来更好地识别和定位目标物体。然而CBAM模块需要额外的计算量来计算通道和空间注意力权重,这会导致在处理大型图像集时网络速度下降。在YOLOv5网络中添加CBAM模块需要更长的训练时间来学习注意力权重,因此模型的训练时间会有所增加,与此同时,其需要更多的存储空间来存储注意力权重,这会增加训练和推理的内存需求。

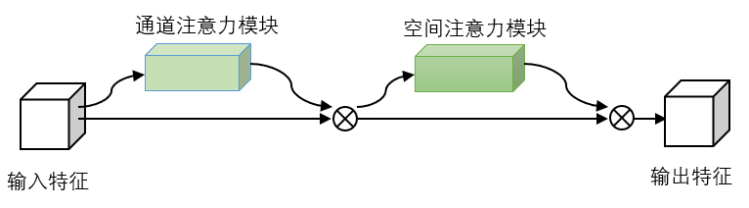
如图3-3所示,本文通过使用CBAM模块替换SPP模块以更好地捕捉图像的上下文信息,帮助优化模型的性能。CBAM模块是一种用于图像分类和目标检测的注意力机制,包括两个部分:通道注意力和空间注意力[21]。通道注意力通过全局平均池化操作和全连接层来计算每个通道的权重,而空间注意力则先进行两次卷积操作,再使用全连接层和激活函数计算每个位置的权重,以引入上下文信息。最终,通道注意力和空间注意力的输出相加,并使用一个2×2的卷积层进行调整,得到最终的CBAM模块输出。该模块可以有效地帮助模型捕捉输入特征图中的关键区域响应和上下文信息,提高模型的性能和检测精度。在实际应用中,CBAM模块常被用于图像分类和目标检测等任务中,它具有良好的可扩展性和适应性,可以适用于多种不同类型的神经网络架构。
3.4 本章小结
本章节首先针对电动车头盔佩戴检测数据集进行了分析,包括数据集来源以及需要检测的三个类别:helmet、without和two_wheeler。同时指出了数据集存在的样本不均衡问题和小型目标数量较多的问题,并介绍了当前采用的YOLOv5模型在该数据集上的缺陷。最后针对本章前面提到的问题,提出了属于数据预处理的Mosaic-9数据增强和属于网络结构替换的添加CBAM注意力机制这两个方面的改进。第四章将会基于这些改进进行实验,并且对比YOLOv5模型改进前后的差别,分析改进前后的优点与不足。
第4章 模型训练与检验
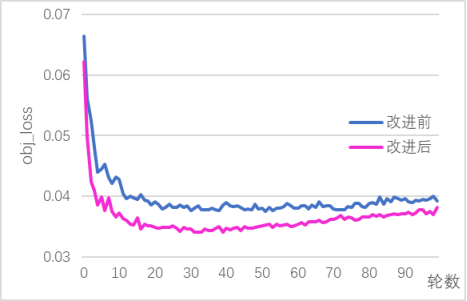
本文利用PyTorch框架实现YOLOv5模型的改进,并在此基础上对模型性能和检测效果进行了分析。PyTorch是Facebook开源AI框架之一,它具有易学易用、可读性高、支持动态计算图和GPU加速等优点,且拥有强大的社区支持。本章将讨论训练和实验所使用的硬件平台以及对改进前后的模型进行比较分析。


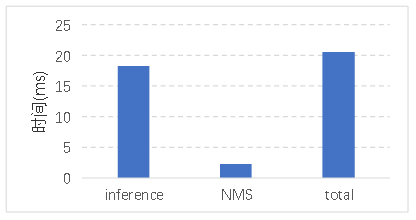

其余完整内容请下载











暂无评论内容