
资源概况
购买将获得:完整无水印论文(查重率30%以下)
其他注意:一经购买,概不退款,不提供指导,每年数量有限3份,售完为止。
配套数据集、检测识别模型、完整系统购买,请移步:https://www.csds.chat/2740.html
资源介绍(截取部分,完整请购买)

摘 要:随着公共安全问题的日益突出,施工工地上安全帽佩戴情况的监测对于保障工人生命安全和维护工地安全管理具有重要意义。当前,传统的安全帽佩戴检测方法依赖人工检查,存在工作效率低下、主观性强、难以实时监督等问题。近年来,计算机视觉和深度学习技术的快速发展为安全帽佩戴检测提供了新的思路。YOLOv8作为YOLO系列目标检测算法的最新版本,以其高效、快速的特点在实时物体检测领域得到了广泛应用。本文提出了一种基于深度学习YOLOv8的工地安全帽佩戴检测系统,并利用PyQt5框架构建了用户友好的图形用户界面(GUI),以实现对工人安全帽佩戴情况的实时、准确检测。
本文首先介绍了安全帽佩戴检测技术的发展历程以及深度学习在该领域的应用现状,对YOLO系列算法进行了综述。接着,详细阐述了系统的设计方案,包括系统架构、数据预处理、模型设计以及GUI界面设计。在系统实现部分,详细描述了开发环境搭建、模型训练、界面实现以及系统测试的过程。通过实验,验证了所提系统在不同光照、不同场景下的安全帽佩戴检测性能,包括检测精度、速度以及模型的泛化能力。实验结果表明,该系统在保持较高检测准确率的同时,能够实现快速的检测速度,能够满足施工工地实时安全帽佩戴检测的需求。最后,本文总结了研究成果,并对未来的研究方向进行了展望。该研究不仅为工地上安全帽佩戴的实时检测提供了一种有效的解决方案,也为深度学习在计算机视觉领域的应用提供了新的视角。
关键词:目标检测 深度学习 YOLOv8 安全帽检测
1 引言
详见下载
2 相关工作综述
详见下载
3 系统设计与实现
该工地安全帽佩戴检测系统的开发主要由深度学习模型训练和可视化操作界面开发两部分组成,其开发流程如图3.1所示。

3.1 环境搭建(详见下载)
3.2 深度学习模型训练
3.2.1数据集制作与分析
本次工地安全帽佩戴检测数据集由网络中收集,如图3.2所示,使用LabelImg工具进行图像标注,其过程涉及以下步骤:打开图像、创建一个新的标注文件、选择预定义类别、在图像上绘制边界框、保存标注结果。这个过程虽然简单,但对于创建高质量的训练数据集至关重要。通过LabelImg绘制矩形框来标记图像中的对象,并为每个对象分配相应的类别标签,可以有效地准备用于训练机器学习模型的数据,从而提高模型的性能和准确性。数据集先标注为XML格式,标注完成后需要借助Python脚本将数据集标签由XML格式转换为YOLO格式。

不同图像的尺寸可能不同,坐标归一化可以将所有图像的边界框坐标统一到相同的尺度范围(0-1),便于模型学习和处理。归一化后的坐标不受图像尺寸的影响,使得模型在不同尺寸的图像上都能更好地泛化。YOLO数据集的标注格式通常为class x_center y_center width height,其中x_center和y_center是边界框中心点的坐标,width和height是边界框的宽度和高度。这些坐标需要进行归一化处理,首先需要计算中心点坐标,中心点的x坐标归一化公式为:x_center = (xmin + xmax) / (2 * img_w),其中xmin和xmax是边界框的左上角和右下角的x坐标,img_w是图像的宽度。中心点的 y 坐标归一化公式为:y_center = (ymin + ymax) / (2 * img_h),其中ymin和ymax是边界框的左上角和右下角的y坐标,img_h是图像的高度;接着需要计算宽度和高度,宽度归一化公式为:width = (xmax – xmin) / img_w,高度归一化公式为:height = (ymax – ymin) / img_h。通过坐标归一化,YOLO模型能够更好地处理不同尺寸的图像,从而提高模型的训练效率和检测性能。如下是将像素坐标转换为 YOLO 归一化坐标的 Python 函数:
def coordinates2yolo(xmin, ymin, xmax, ymax, img_w, img_h):
x = round((xmin + xmax) / (2.0 * img_w), 6)
y = round((ymin + ymax) / (2.0 * img_h), 6)
w = round((xmax - xmin) / img_w, 6)
h = round((ymax - ymin) / img_h, 6)
return x, y, w, h
处理好后再编写Python脚本将数据集随机划分为训练集、验证集和测试集,本设计划分的比例为8:1:1。这种划分方式有助于避免模型过拟合。训练集用于模型的学习,而验证集则在训练过程中提供独立的评估反馈,帮助发现并调整模型的过拟合问题,例如通过修改模型结构或调整正则化参数。测试集则在模型训练和调整完成后,用于客观评估模型对未知数据的泛化能力,确保模型在实际应用中的有效性。其次,这种划分方式能够提高模型的泛化能力。通过随机划分,可以保证训练集、验证集和测试集的数据分布具有相似性,从而使模型在训练过程中接触到数据集中的各种情况,学习到更广泛的数据特征和规律。同时,验证集和测试集为模型提供了独立的评估环境,帮助模型更好地适应各种未知情况,而不是仅在训练集上表现出色。此外,验证集还可以用于优化模型选择和参数调整。在机器学习项目中,验证集可以比较不同模型的性能,帮助选择最适合当前任务的模型,同时用于调整模型的参数,如学习率、正则化系数等。这种基于验证集的反馈机制能够有效提高模型的性能,而测试集则用于最终评估调整后的模型性能。 脚本代码如下:
import os
import shutil
import random
# 源文件夹路径
source_dir = r'C:\Users\PC\Desktop\YOLO\img'
# 目标文件夹路径
target_dirs = [
r'C:\Users\PC\Desktop\新建文件夹\train\images',
r'C:\Users\PC\Desktop\新建文件夹\valid\images',
r'C:\Users\PC\Desktop\新建文件夹\test\images'
]
# 确保目标文件夹存在
for dir_path in target_dirs:
if not os.path.exists(dir_path):
os.makedirs(dir_path)
# 获取源文件夹中所有图片文件
images = [f for f in os.listdir(source_dir) if os.path.isfile(os.path.join(source_dir, f))]
# 分配比例
train_ratio = 8
valid_ratio = 1
test_ratio = 1
total_ratio = train_ratio + valid_ratio + test_ratio
# 分配图片
for image in images:
# 随机生成一个介于0和total_ratio之间的数
ratio = random.randint(0, total_ratio - 1)
# 根据比例分配到不同的文件夹
if ratio < train_ratio:
target_dir = target_dirs[0]
elif ratio < train_ratio + valid_ratio:
target_dir = target_dirs[1]
else:
target_dir = target_dirs[2]
# 构建完整的源文件和目标文件路径
source_image = os.path.join(source_dir, image)
target_image = os.path.join(target_dir, image)
# 复制文件
shutil.copy2(source_image,target_image)
处理完成的数据集规模相当庞大,总共有6026张图片用于模型的训练阶段,而为了评估模型的泛化能力,还特别划分了763张图片用于验证集,以及792张图片用于测试集。这些图片涵盖了工地安全帽佩戴数据集中的复杂场景,包括了白天、夜间、室内、室外、公众场所等多种环境,图片中既有单人场景也有多人场景,确保了数据集的多样性和复杂性。在这些图片中,检测的类别专注于“hat”(佩戴安全帽)和“person”(未佩戴安全帽),数据集中包含了超过80000个工地未佩戴安全帽目标和接近10000个佩戴安全帽目标,这为训练一个精准的工地安全帽佩戴检测模型提供了丰富的样本。通过分析图3.3左上角的图表,我们可以看到类别的样本数量非常充足,这有助于模型学习到不同情况下的工地安全帽佩戴特征。而图3.3右上角的图表则展示了训练集中边界框的大小分布以及相应数量,这有助于我们了解工地安全帽佩戴目标在图片中的尺寸变化,以及不同尺寸目标的频率。这些信息对于模型在处理不同大小的工地安全帽佩戴时的准确性至关重要。图3.3左下角的图表描述了边界框中心点在图像中的位置分布情况,这有助于我们了解工地安全帽佩戴在图片中的位置分布,是否均匀分布,或者倾向于集中在图片的某个区域。这对于模型在不同位置都能准确检测到工地安全帽佩戴非常关键。最后,图3.3右下角的图表反映了训练集中目标高宽比例的分布状况,了解工地安全帽佩戴目标的高宽比例分布对于模型的准确性至关重要,因为不同角度和姿态的工地安全帽佩戴可能会导致不同的高宽比。

其余完整内容详见下载

3.3 可视化操作界面开发
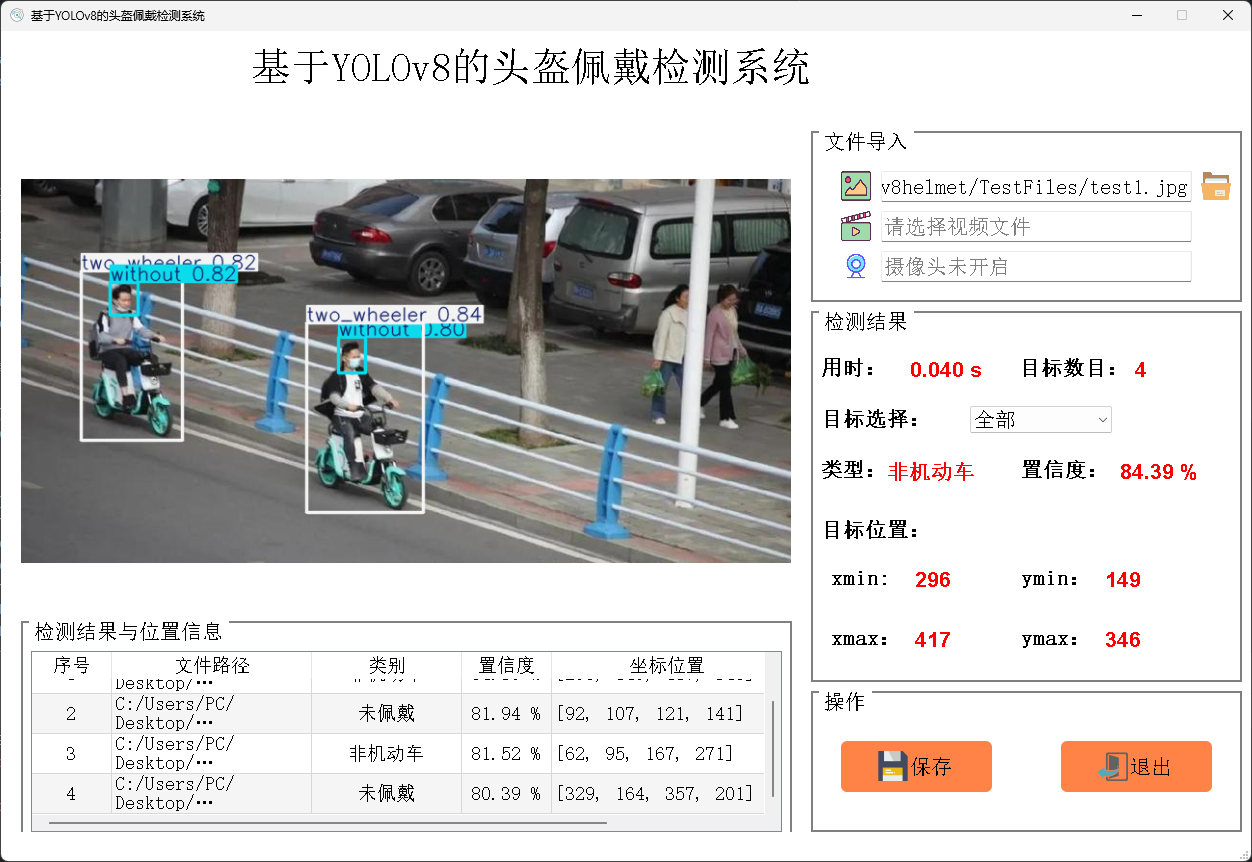
基于深度学习的工地安全帽佩戴检测系统的模块框图如图3.6所示。主要包括文件导入模块、检测模块、检测结果选择模块、检测结果表格模块和操作模块,共五大模块。文件导入模块负责让用户选择检测源,用户可以跟进需求选择检测图片、视频或开启视像头实时检测。检测模块则是核心模块,其通过加载训练好的深度学习模型对预处理过的检测源进行推理,在检测源上绘制目标推理框,并在系统界面的中心区域显示出来供用户参考。检测结果模块则是考虑到推理结果可能包含多个目标,用户可以通过该模块快速选择并定位到该目标,查看该推理目标的类型、置信度、位置坐标信息等,除此之外,该模块还统计了模型对本次检测源检测用时和检测结果中目标数量。检测结果表格模块则是以表格的形式记录了每个检测源的文件路径和每个目标的置信度等信息。用户通过点击操作模块中的“保存”,可以将本次检测结果保存至该项目目录下的Save_data文件夹里;“关闭”则是将该系统关闭。

首先是借助Qt Designer拖拽式放置控件进行界面设计。接着借助pyuic5工具将.ui文件转换为Python代码,以便在PyQt5应用程序中使用,经统计,共使用了11种不同类型的控件,数量最多的是QtWidgets.QLabel和QtWidgets.QLineEdit,各用了4个。最后,在PyQt5的Python代码中,加载.ui文件或转换后的Python代码,创建和管理控件实例,并编写相应的事件处理逻辑,如该设计中的图片、视频、摄像头加载和处理,检测对象的选择,检测目标置信度、位置坐标等信息的显示,以及检测结果的保存。与此同时,使用OpenCV库加载训练好的YOLO模型,并在模型推理后,对模型的输出进行解析,提取边界框、置信度和类别信息,在原始图像上绘制边界框和类别标签,并在相应输出窗口显示坐标信息等。
工地安全帽佩戴检测系统基于PyQt5实现的逻辑如下,首先是加载UI布局文件Ui_MainWindow,并初始化应用程序的主窗口,设置按钮和下拉菜单的信号与槽,使得当用户进行操作时,程序能够响应并执行相应的函数,通过加载CSS文件来美化应用程序的界面;接着使用训练好的YOLO模型进行目标检测,检测结果包括目标的边界框、类别、置信度等信息,这些信息会显示在界面上的表格和图片预览区域。

用户可以通过“文件导入”区域的两个小图标分别选择图片检测和视频检测,检测流程如图3.7所示;通过模型推理后,具有检测框的检测结果将直接显示在左侧区域,而检测结果的信息则在“检测结果”区域输出,其中包括推理用时、目标数量、目标类型、置信度和目标坐标,而“目标选择”下拉框则可以选择要查看的目标对象,可以根据需要选择全部或者某个目标;在界面的左下方,则通过表格的形式清晰明了地输出检测的结果信息;界面右下方的“操作”区域的“保存”按钮可以将检测结果保存到本地,“退出”按钮则关闭该系统。
如图3.8所示即为该系统最终开发完成的可视化操作界面。

4 模型训练与指标分析
完整内容详见下载
4.2训练的模型分析




2 总结与展望
其余完整内容详见下载









暂无评论内容