
资源概况
购买将获得:完整无水印论文(查重率30%以下)
其他注意:一经购买,概不退款,不提供指导,每年数量有限3份,售完为止。
配套数据集、检测识别模型、完整系统购买,请移步:https://www.csds.chat/2859.html
资源介绍(截取部分,完整请购买)


摘 要:随着人工智能技术的飞速发展,深度学习在图像识别与处理领域取得了重大突破,尤其在交通标识识别方面展现出巨大潜力。交通标识识别作为智能交通系统中的关键环节,对于提高交通安全、优化交通管理具有重要意义。本文提出了一种基于深度学习的交通标识识别系统,该系统采用先进的YOLOv8算法作为核心检测模型,并利用PyQt5框架构建了用户友好的图形用户界面(GUI)。YOLOv8算法凭借其高效的检测速度和较高的准确率,在实时交通标识识别领域具有显著优势,而PyQt5则为系统提供了一个直观且交互性强的操作界面。
本文首先介绍了交通标识识别技术的发展背景和深度学习在该领域的应用现状,并对YOLO系列算法进行了综述。接着,详细阐述了系统的设计方案,包括系统架构、数据预处理、模型设计以及界面设计。在系统实现部分,描述了环境搭建、模型训练、界面实现以及系统测试的过程。通过实验验证了所提系统在不同场景下的交通标识识别性能,包括识别精度、速度和模型的泛化能力。实验结果表明,该系统在保持较高识别准确率的同时,能够实现快速的识别速度,满足实时交通标识识别的需求。最后,本文总结了研究成果,并对未来的研究方向进行了展望。该研究不仅为实时交通标识识别提供了一种有效的解决方案,也为深度学习在智能交通领域的应用提供了新的思路。
关键词:目标检测 深度学习 YOLOv8 交通标识识别
1 引言
1.1 研究背景和意义
随着城市化进程的加速和交通流量的不断增加,交通标识识别技术在智能交通系统中的重要性日益凸显。交通标识是道路安全和交通管理的关键组成部分,其正确识别对于驾驶员的驾驶行为、自动驾驶系统的决策以及交通流量的优化都有着至关重要的影响[1]。然而,传统的交通标识识别系统面临着诸多挑战,例如交通标识的多样性、复杂背景下的识别难度、实时性要求等[2]。
近年来,深度学习技术的快速发展为交通标识识别带来了新的机遇。深度学习模型,尤其是卷积神经网络(CNN)和目标检测算法(如YOLO系列),在图像识别领域取得了显著的成果。YOLOv8作为一种最新的目标检测算法,以其高效的检测速度和较高的准确率,在实时交通标识识别中展现出巨大潜力。此外,深度学习模型能够通过大量的标注数据进行训练,从而在复杂场景下实现高精度的交通标识识别。
准确识别交通标识能够帮助驾驶员更好地遵守交通规则,减少因标识误读或未读而导致的交通事故。对于自动驾驶车辆而言,可靠的交通标识识别系统是实现安全驾驶的关键技术之一。交通标识识别系统可以为交通管理部门提供实时的交通信息,帮助优化交通信号控制和道路规划。例如,通过识别交通标识的状态和位置,可以及时发现标识的损坏或缺失,从而提高交通管理的效率。
自动驾驶车辆依赖于高精度的环境感知系统,交通标识识别是其中的重要环节。基于深度学习的交通标识识别系统能够为自动驾驶车辆提供可靠的标识信息,从而支持其决策和路径规划。传统的交通标识识别系统在实时性和复杂场景下的表现往往不尽如人意。而基于深度学习的系统,如改进的YOLOv8算法,通过引入小目标检测层和多尺度特征融合机制,能够显著提高识别的准确率和实时性。此外,深度学习模型通过大量的数据训练,具有更好的泛化能力,能够适应不同的道路环境和天气条件。
综上所述,基于深度学习的交通标识识别系统不仅能够有效提升交通安全和交通管理效率,还为自动驾驶技术的发展提供了重要的技术支持。随着深度学习技术的不断进步,交通标识识别系统的性能将进一步提升,为智能交通系统的全面实现奠定坚实基础[3]。
1.2 研究内容和目标
1.2.1研究内容
本研究旨在开发一个基于深度学习的交通标识识别系统,具体内容和目标如下:
(1)系统设计与架构:设计一个高效的交通标识识别系统架构,结合YOLOv8算法和PyQt5图形用户界面(GUI),实现实时交通标检测和识别功能。研究系统的各个功能模块,包括数据预处理、模型训练、界面设计等。
(2)数据预处理:收集和整理交通标识图像数据集,进行数据清洗和标注。实施数据增强技术,以提高模型的泛化能力和鲁棒性。
(3)模型选择与训练:选择YOLOv8作为核心检测模型,分析其网络结构和训练策略。进行模型训练,调优超参数,以优化检测精度和速度。
(4)系统实现与测试:使用PyQt5开发用户友好的图形界面,使用户能够方便地进行交通标识识别操作。对系统进行全面测试,包括检测精度、速度和用户体验等方面的评估。
(5)实验与结果分析:通过实验验证所提系统在不同场景下的交通标识识别性能,分析检测结果的准确性和实时性。探讨YOLOv8模型的优势和不足。
(6)总结与展望:总结研究成果,分析系统的创新点和应用前景。提出未来可能的研究方向和改进建议。
1.2.2研究目标
本研究的主要目标是构建一个高效、准确且易于使用的交通标识识别系统,能够在实时应用中满足用户需求。通过深入分析和实验验证,期望为深度学习在交通标识识别领域的应用提供新的思路和方法。最终,推动交通标识识别技术在智能交通、自动驾驶等实际场景中的广泛应用。
1.3 论文结构安排
本论文共分为六章,具体结构安排如下:
第一章 引言。本章介绍研究背景、研究意义、研究内容和目标,阐明本论文的研究动机和目的。
第二章 相关工作综述。本章回顾交通标识识别技术的发展历程,综述深度学习在交通标识识别中的应用,详细介绍YOLO系列算法的演变及其优缺点,并探讨PyQt5在图形用户界面开发中的应用。
第三章 系统设计。本章详细描述所提交通标识识别系统的设计方案,包括系统架构、功能模块划分、数据预处理方法、模型设计及PyQt5界面设计。
第四章 系统实现。本章介绍系统的具体实现过程,包括环境搭建、模型训练、界面实现及系统测试,详细阐述每个模块的实现细节。
第五章 实验结果与分析。本章展示实验设置、实验结果及其分析,分析该交通标识识别模型的性能,讨论检测精度、速度和模型的泛化能力等。
第六章 结论与展望。本章总结研究成果,分析研究的创新点与不足之处,并对未来的研究方向进行展望。
通过上述结构安排,论文将系统地展示基于深度学习的交通标识识别系统的研究过程和成果,帮助读者全面理解本研究的核心内容和贡献。
2 相关工作综述
完整内容详见下载
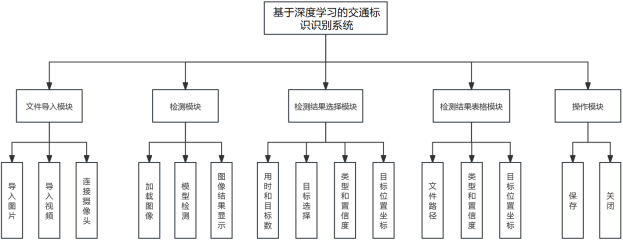
3 系统设计与实现
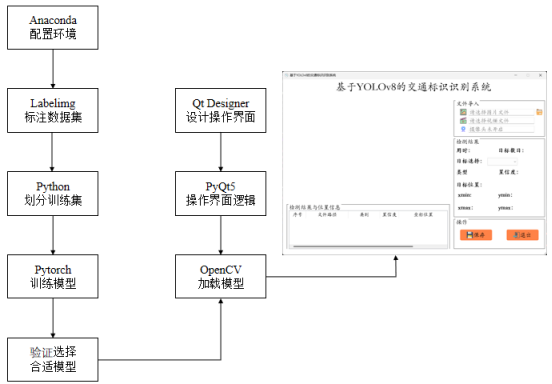
该交通标识识别系统的开发主要由深度学习模型训练和可视化操作界面开发两部分组成,其开发流程如图3.1所示。
3.1 环境搭建
3.2 深度学习模型训练
3.2.1数据集制作与分析
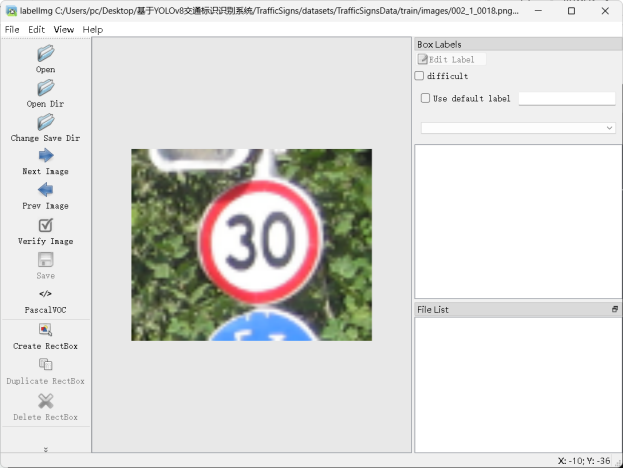
本次鲜花识别数据集由网络中收集,如图3.2所示,使用LabelImg工具进行图像标注,其过程涉及以下步骤:打开图像、创建一个新的标注文件、选择预定义类别、在图像上绘制边界框、保存标注结果。这个过程虽然简单,但对于创建高质量的训练数据集至关重要。通过LabelImg绘制矩形框来标记图像中的对象,并为每个对象分配相应的类别标签,可以有效地准备用于训练机器学习模型的数据,从而提高模型的性能和准确性。数据集先标注为XML格式,标注完成后需要借助Python脚本将数据集标签由XML格式转换为YOLO格式。
不同图像的尺寸可能不同,坐标归一化可以将所有图像的边界框坐标统一到相同的尺度范围(0-1),便于模型学习和处理。归一化后的坐标不受图像尺寸的影响,使得模型在不同尺寸的图像上都能更好地泛化。YOLO数据集的标注格式通常为class x_center y_center width height,其中x_center和y_center是边界框中心点的坐标,width和height是边界框的宽度和高度。这些坐标需要进行归一化处理,首先需要计算中心点坐标,中心点的x坐标归一化公式为:x_center = (xmin + xmax) / (2 * img_w),其中xmin和xmax是边界框的左上角和右下角的x坐标,img_w是图像的宽度。中心点的 y 坐标归一化公式为:y_center = (ymin + ymax) / (2 * img_h),其中ymin和ymax是边界框的左上角和右下角的y坐标,img_h是图像的高度;接着需要计算宽度和高度,宽度归一化公式为:width = (xmax – xmin) / img_w,高度归一化公式为:height = (ymax – ymin) / img_h。通过坐标归一化,YOLO模型能够更好地处理不同尺寸的图像,从而提高模型的训练效率和检测性能。如下是将像素坐标转换为 YOLO 归一化坐标的 Python 函数:
def coordinates2yolo(xmin, ymin, xmax, ymax, img_w, img_h):
x = round((xmin + xmax) / (2.0 * img_w), 6)
y = round((ymin + ymax) / (2.0 * img_h), 6)
w = round((xmax - xmin) / img_w, 6)
h = round((ymax - ymin) / img_h, 6)
return x, y, w, h
处理好后再编写Python脚本将数据集随机划分为训练集、验证集和测试集,本设计划分的比例为8:1:1。这种划分方式有助于避免模型过拟合。训练集用于模型的学习,而验证集则在训练过程中提供独立的评估反馈,帮助发现并调整模型的过拟合问题,例如通过修改模型结构或调整正则化参数。测试集则在模型训练和调整完成后,用于客观评估模型对未知数据的泛化能力,确保模型在实际应用中的有效性。其次,这种划分方式能够提高模型的泛化能力。通过随机划分,可以保证训练集、验证集和测试集的数据分布具有相似性,从而使模型在训练过程中接触到数据集中的各种情况,学习到更广泛的数据特征和规律。同时,验证集和测试集为模型提供了独立的评估环境,帮助模型更好地适应各种未知情况,而不是仅在训练集上表现出色。此外,验证集还可以用于优化模型选择和参数调整。在机器学习项目中,验证集可以比较不同模型的性能,帮助选择最适合当前任务的模型,同时用于调整模型的参数,如学习率、正则化系数等。这种基于验证集的反馈机制能够有效提高模型的性能,而测试集则用于最终评估调整后的模型性能。 脚本代码如下:
import os
import shutil
import random
# 源文件夹路径
source_dir = r'C:\Users\PC\Desktop\YOLO\img'
# 目标文件夹路径
target_dirs = [
r'C:\Users\PC\Desktop\新建文件夹\train\images',
r'C:\Users\PC\Desktop\新建文件夹\valid\images',
r'C:\Users\PC\Desktop\新建文件夹\test\images'
]
# 确保目标文件夹存在
for dir_path in target_dirs:
if not os.path.exists(dir_path):
os.makedirs(dir_path)
# 获取源文件夹中所有图片文件
images = [f for f in os.listdir(source_dir) if os.path.isfile(os.path.join(source_dir, f))]
# 分配比例
train_ratio = 8
valid_ratio = 1
test_ratio = 1
total_ratio = train_ratio + valid_ratio + test_ratio
# 分配图片
for image in images:
# 随机生成一个介于0和total_ratio之间的数
ratio = random.randint(0, total_ratio - 1)
# 根据比例分配到不同的文件夹
if ratio < train_ratio:
target_dir = target_dirs[0]
elif ratio < train_ratio + valid_ratio:
target_dir = target_dirs[1]
else:
target_dir = target_dirs[2]
# 构建完整的源文件和目标文件路径
source_image = os.path.join(source_dir, image)
target_image = os.path.join(target_dir, image)
# 复制文件
shutil.copy2(source_image,target_image)
处理完成的数据集规模相当庞大,总共有5998张图片用于模型的训练阶段,而为了评估模型的泛化能力,还特别划分了617张图片用于验证集,以及606张图片用于测试集。这些图片涵盖了复杂场景,包括了白天、夜间、晴天、雨天等多种环境,确保了数据集的多样性和复杂性。在这些图片中,检测的类别包括Speed_Limit_5(限速5km/h)、Speed_Limit_15(限速15km/h)、Speed_Limit_30(限速30km/h)、Speed_Limit_40(限速40km/h)、Speed_Limit_50(限速50km/h)、Speed_Limit_60(限速60km/h)、Speed_Limit_70(限速70km/h)、Speed_Limit_80(限速80km/h)、No_Go_Straight_And_No_Left_Turn(禁止直行和左转)、No_Go_Straight_And_No_Right_Turn(禁止直行和右转)、No_Go_Straight(禁止直行)、No_Left_Turn(禁止左转)、No_Left_Turn_And_No_Right_Turn(禁止左转和右转)、No_Right_Turn(禁止右转)、No_Overtaking(禁止超车)、No_U_Turn(禁止掉头)、No_Entry_for_Motor_Vehicles(禁止机动车驶入)、No_Honking(禁止鸣喇叭)、Removal_of_Speed_Limit_40(解除40km/h限速)、Removal_of_Speed_Limit_50(解除50km/h限速)、Straight_And_Right_Turn(直行和右转)、Straight(直行)、Left_Turn(左转)、Left_And_Right_Turn(左转和右转)、Right_Turn(右转)、Keep_Left(保持左侧行驶)、Keep_Right(保持右侧行驶)、Roundabout(环岛)、Motor_Vehicles_Only(机动车行驶)、Horn_OK(鸣喇叭)、Non_Motor_Vehicle(非机动车行驶)、U_Turn(调头)、Detour_Left_Or_Right(左右绕行)、Traffic_Lights(注意交通信号灯)、Caution(注意危险)、Caution_Pedestrians(注意行人)、Caution_Bicycles(注意非机动车)、Caution_Children(注意儿童)、Sharp_Right_Turn(向右急转弯)、Sharp_Left_Turn(向左急转弯)、Downhill_Slope(下陡坡)、Steep_Uphill(上陡坡)、Slow_Down(慢行)、T_Intersection_Right(右T型路口)、T_Intersection_Left(左T型路口)、Village(村庄)、Reverse_Curve(反向弯路)、Unattended_Railway_Crossing(无人看守铁道路口)、Road_Works(施工)、Continuous_Bends(连续转弯)、Guarded_Railway_Crossing(有人看守铁道路口)、Accident_Prone_Area(事故易发路段)、Stop_Sign(停车让行)、No_Through_Road(禁止通行)、No_Parking(禁止停车)、No_Entry(禁止驶入)、Yield_Sign(减速让行)、Parking_Check(停车检查)共58类,这为训练一个精准的交通标识识别模型提供了丰富的样本。
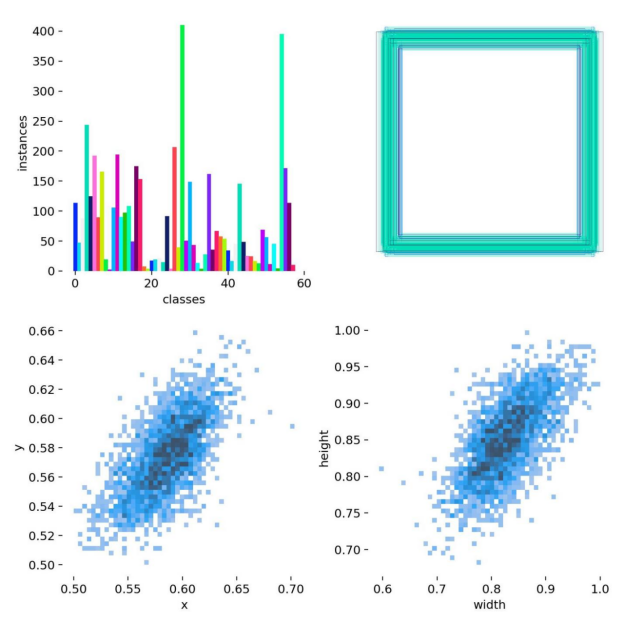
通过分析图3.3左上角的图表,我们可以看到各类别的样本数量,这有助于模型学习到不同类别标识的特征。而图3.3右上角的图表则展示了训练集中边界框的大小分布以及相应数量,这有助于我们了解标识目标在图片中的尺寸变化,以及不同尺寸目标的频率。这些信息对于模型在处理不同类别的标识时的准确性至关重要。图3.3左下角的图表描述了边界框中心点在图像中的位置分布情况,这有助于我们了解标识目标在图片中的位置分布,是否均匀分布,或者倾向于集中在图片的某个区域。这对于模型在不同位置都能准确检测到标识非常关键。最后,图3.3右下角的图表反映了训练集中目标高宽比例的分布状况,了解标识目标的高宽比例分布对于模型的准确性至关重要,因为不同角度的标识可能会导致不同的高宽比。
其余完整内容详见下载
3.3 可视化操作界面开发

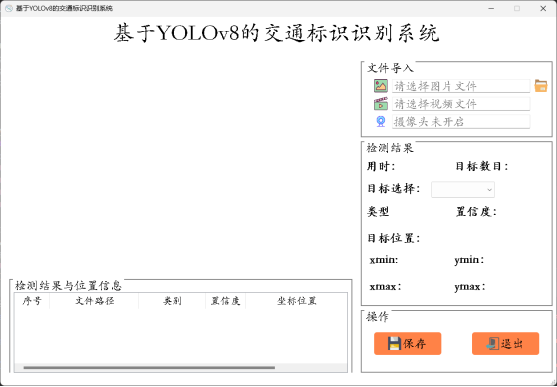
4 模型训练与指标分析
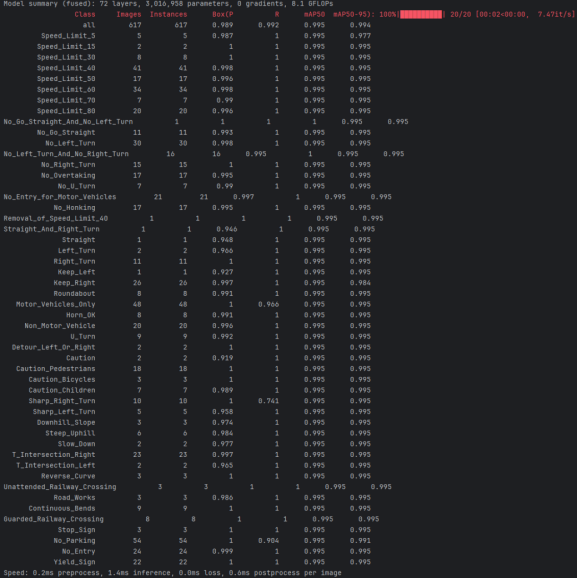
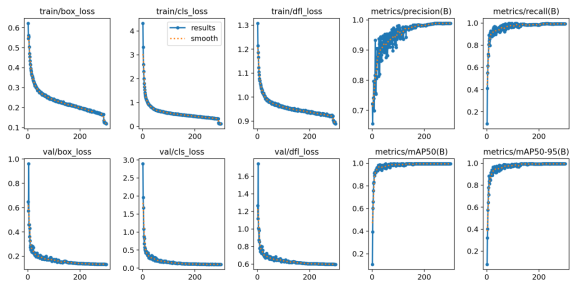
如图4.1所示,本系统中训练的基于YOLOv8训练的交通标识识别模型的精确率达到了98.9%,模型的召回率达到99.2%,与此同时,均值平均精确率达到了99.4%。
训练初期,模型的精确率较低,因为模型刚开始学习,尚未从训练数据中学习到足够的特征。随着训练的进行,精确率迅速上升,表明模型正在改进,更好地区分不同类别的交通标识。在200轮之后,精确率的提高放缓,进入一个稳定阶段,这表明模型已经学习到大部分有用特征,并且性能正在趋于稳定。模型的精确率达到的98%以上。说明模型在推理交通标识目标时预测正类时很少出现错误,即产生的假正例较少,这意味着模型在识别特定目标时更加准确和可靠;且精确度较高表明模型在识别目标时具有较高的准确性,能够准确地区分目标和背景,减少误判。在目标检测任务中,高精确度通常意味着模型性能较好,因为它表明模型能够有效地识别和定位感兴趣的目标。
99.2%的召回率说明模型在交通标识的推理上具有较高的检测覆盖,即模型能够检测到大多数甚至所有的实际正类样本,这意味着模型在识别交通标识目标方面具有较强的能力,能够捕捉到更多的目标对象;且较高的召回率表明模型在预测时较少错过正类样本,即漏检(Miss)的情况较少,这对于需要高检测敏感性的应用场景非常重要,在智能交通领域需要尽可能地检测出所有目标,该模型的高召回率能够满足这一需求。99.4%的均值平均精确率则说明模型在较高的IoU阈值下具有较好的检测性能,即模型能够更准确地定位交通标识目标对象。
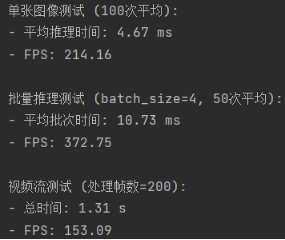
在对基于 YOLOv8 的交通标识识别分类系统进行性能测试时,我们分别从单张图像测试、批量推理测试以及视频流测试三个维度进行了评估。如图4.4所示,在单张图像测试中,经过100次平均计算,系统的平均推理时间为4.67毫秒,对应的帧率(FPS)达到了214.16。而在批量推理测试环节,当设置批次大小为4并进行50次平均计算后,平均批次时间为10.73毫秒,此时的帧率提升至372.75,这表明系统在处理批量图像时能够更高效地利用计算资源,从而显著提高了处理速度。至于视频流测试,系统处理了200帧图像,总耗时为1.31秒,计算得出的帧率为153.09。通过以上测试结果可以看出,该交通标识识别分类系统在不同的测试场景下均展现出了良好的性能表现,能够满足实际应用中对交通标识识别分类任务的实时性要求。

如图4.5为训练好的模型对于输入的图片的检测结果,可以看出图片中的交通标识都被检测出来了。且该图片中交通标识目标较模糊,有复杂背景干扰。但该模型不仅能够在模糊背景的图片中检测出目标,而且因为其较高的召回率,使得其能够尽可能地检测出所有的目标,即“限速30km/h”和“注意儿童”。对于严谨的交通安全等领域,其具有较高的符合性,因此最终选择YOLOv8训练的模型作为该交通标识识别系统的深度学习核心模型。
其余完整内容详见下载










暂无评论内容